

Hier geht's zu dieser Seite

Die vorliegenden Materialien wurden von Daniel Hoherz und André Tempel erstellt. Sollten andere Editoren die Materialien erstellt haben, werden diese explizit genannt.
 Die Aufgaben 1 und 2 wurden nach einer Idee von A. Grillenberger erstellt.
Die Aufgaben 1 und 2 wurden nach einer Idee von A. Grillenberger erstellt.
Dem US-Einzelhandelsriesen Target gelang es durch die Analyse herauszufinden,
welche Kundinnen schwanger sind. Duhigg schreibt, dies sei für das Unternehmen
sehr wichtig gewesen, denn werdende Eltern seien so etwas wie
der „Heilige Gral“ für Unternehmen wie Target. In einer Schwangerschaft änderten
sich die Gewohnheiten, und wer vorher keine gute Kundin des Einzelhändlers
gewesen sei, könne es danach werden – wenn man ihr zu richtigen
Zeit die richtige Werbung zusendet.
Die Statistiker von Target, so berichtet es Duhigg, identifizierten etwa 25 Produkte, die darauf hinweisen,
dass Kundinnen schwanger sind. Genauer gesagt, wenn sie sich im zweiten Trimester ihrer
Schwangerschaft befinden. Denn zu diesem Zeitpunkt fingen sie an, sich neue Sachen zu kaufen,
und Target schickte ihnen dann schon Werbung. Zu den identifizierten Produkten gehörten parfümfreie
Körperlotion, große Mengen an Watte und Nahrungsergänzungsmittel wie Kalzium, Magnesium
und Zink. Target habe in der Kundendatenbank gesucht und Zehntausende Frauen gefunden,
die mit großer Wahrscheinlichkeit bald Mutter würden.
Der Autor Duhigg berichtet darüber, wie die Werbung für Schwangerschaftsprodukte den Vater einer
Tochter in Rage versetzte. Er beschwerte sich in einem Target-Markt in der Nähe von Minneapolis
darüber, dass seine Tochter – noch ein Teenager – Werbung für Babykleidung erhalten habe.
Ob man sie dazu animieren wolle, schwanger zu werden, fragte er den Manager des Ladens. Dieser
entschuldigte sich, doch als er später noch einmal sein Bedauern zum Ausdruck bringen wollte und
den Vater anrief, stellte sich heraus, dass die Tochter wirklich schwanger war. Target hatte es nur
vor dem Vater der jungen Frau gewusst.

Frankfurter Neue Presse, 13.09.2014
Im Unterricht haben Sie bereits einen Artikel darüber gesehen,
wie Daten heute im Einzelhandel verwendet
werden, um Kunden auf sie zugeschnittene Werbung
präsentieren zu können. Onlineshops gehen heute jedoch
schon weiter und versuchen, ihren Kunden viele
Produkte möglichst schnell liefern zu können:
Noch bevor ein Kunde überhaupt den Button “Kaufen” anklickt, soll die für ihn passende Ware
schon auf dem Weg in Richtung seiner Wohnung sein. Dem Versandhändler Amazon wurde ein Patent
zugesprochen, das einen „vorausschauenden Versand“ („anticipatory shipping“) ermöglichen
soll. Das heißt: Bestimmte Waren werden schon einmal an ein Versandzentrum geschickt, in dessen
Nähe sich ein oder mehrere Kunden höchstwahrscheinlich für das Produkt interessieren. Wird es
dann schließlich bestellt, ist es umso schneller beim Empfänger.

Spiegel Online, 18.01.2014
- In der unteren Abbildung siehst du den sehr reduzierten Ausschnitt einer Tabelle mit Daten von 15 Kundinnen
und Kunden eines Onlinehändlers.
Ein Tool zur automatisierten Datenanalyse hat aufgrund der gesammelten Daten in den ersten acht Spalten
eine Vorhersage zum nächsten gekauften Artikel erstellt.
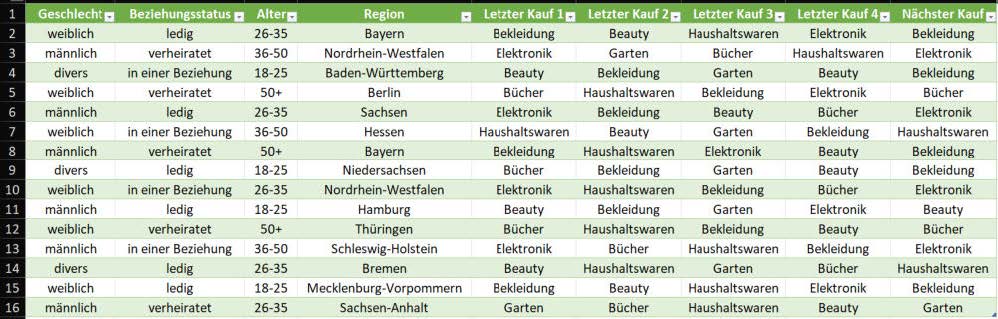
Analysieren Sie die Daten der ersten acht Spalten auf Gemeinsamkeiten in Bezug zur Vorhersage des nächsten Kaufs. Stellen Sie mit ihren Erkenntnissen Regeln der Form: WENN…, DANN ist der nächste Kauf…
Es lässt sich ein Zusammenhang zwischen Menschen im Alter zwischen 15 und 30 und einem erhöhten
Risiko für Sonnenbrände am Körper feststellen.
Man könnte also sagen: Menschen im Alter von 15-30 haben häufiger Sonnenbrände als andere.
Auch ist ein Zusammenhang zwischen der Intensität der Sonnenstrahlen und einer Zunahme des Risikos für
Sonnenbrände festzustellen.
Man könnte also auch sagen: Steigt die Intensität der Sonnenstrahlen, steigt das Risiko für Sonnenbrände an
ungeschützter Haut.
Der Unterschied in beiden Situationen ist, dass beim zweiten Zusammenhang die Sonnenstrahlen tatsächlich
für das erhöhte Risiko verantwortlich sind.
Beim ersten Zusammenhang ist das Alter nur eine Art „Nebenerscheinung“ aber nicht der eigentliche
Grund. Da junge Menschen häufiger als ältere mit ungeschützter Haut im Sommer draußen sind, lässt sich
dieser Zusammenhang erklären. Wichtig ist aber, dass nicht zwingend aus der Tatsache, dass ein Mensch
jung ist, nicht der eigentliche Grund für das erhöhte Risiko für Sonnenbrände ist.
Es gibt bei generell zwei Möglichkeiten, wie Vorhersagen getroffen werden können:
Kausaler Zusammenhang: Es gibt logische Zusammenhänge, sog. Kausalzusammenhänge, die wir zur Vorhersage
nutzen können. Beispiel: Wenn die Sonnenintensität sehr hoch ist, ist das Risiko für Sonnenbrände
hoch.
Korrelativer Zusammenhang: In anderen Bereichen erkennen wir keinerlei logische Zusammenhänge.
Stattdessen können wir nach Mustern in den Daten suchen. Diese liefern uns auch Zusammenhänge, wir
können sie uns aber oft nicht im Detail erklären bzw. die eigentliche Ursache ergründen. Solche Zusammenhänge
bezeichnen wir als korrelative Zusammenhänge.
Beispiel: Wenn ein Mensch jung ist, hat er häufiger Sonnenbrände am Körper.
Kausalzusammenhänge helfen uns zwar dabei Dinge zu verstehen, sie sind aber für Datenanalysen oft relativ
wenig interessant: Sie sind oft offensichtlich und bekannt, sodass sie nur wenig neue Informationen her –
vorbringen. Wir können uns aber logisch erklären, dass sie richtig/wahr sind. Die korrelativen Zusammenhänge
sind daher oft spannender, da sie neue Informationen eröffnen. Sie haben aber den Nachteil, dass sie
nicht unbedingt logisch nachvollziehbar sind: Wie genau Wohnort und Alter das Kaufverhalten prägen,
können wir uns meist nicht logisch erklären. Außerdem müssen wir sie erst finden, was relativ schwierig ist.
Begründen Sie, ob es sich bei den unter Aufgabenteil a) erstellten Regeln und auch bei dem Target- und
Amazon-Beispiel um kausale oder korrelative Zusammenhänge handelt.
Stellen Sie sich folgendes vor: In der Schule würden Sie je Fach nur zwei Arbeiten schreiben und daraus würde ermittelt werden, wie Sie in den zukünftigen Arbeiten abschneiden würden und diese Note würden dann genommen werden. Sie hätten den Vorteil, dass Sie nicht mehr so viele Arbeiten schreiben müssten und die Lehrkraft müsste nicht mehr so viel korrigieren.
- Nehmen Sie spontan Stellung dazu, wie Sie dieses Vorgehen fänden.
- Stellen Sie Vermutungen darüber auf, ob das geht und wie „gut“ das funktionieren würde.


Vergessen Sie nicht: Machen Sie sich Fotos von Ihren Ergebnissen und machen Sie sich dazu Notizen.



Beschreiben Sie die beiden Überschriften und stellen Sie Vermutungen darüber an, weshalb das problematisch ist.