Datenverwaltung

Die vorliegenden Materialien wurden von Daniel Hoherz und André Tempel erstellt. Sollten andere Editoren die Materialien erstellt haben, werden diese explizit genannt.
- Erstellt zu dritt oder viert (arbeitsteilig) in Goodnotes Karteikarten mit den Begriffen und ggf. Abbildungen und den korrekten Beschreibungen und Benennungen dazu, damit ihr diese für die Klassenarbeit nutzen könnt.
- Unten ist eine kleine Datenbank einer Social-Media-Plattform zu sehen. Momentan besteht diese nur aus den beiden Tabellen Nutzer und Posts, also anders formuliert: Es werden sich die Benutzer der Plattform und deren Posts in der Datenbank gespeichert.
Nutzer
Nutzer-ID Name E-Mail Registrierungsdatum Geburtsdatum Wohnort 1 Max max.mustermann@mail.de 10.05.2023 15.03.2005 Berlin 2 Lisa lisa.schmidt@mail.de 15.06.2023 22.07.2006 Hamburg 3 Tom tom.weber@mail.de 20.07.2023 05.11.2005 München 4 Anna anna.huber@mail.de 01.08.2023 30.04.2006 Köln 5 Paul paul.neumann@mail.de 12.09.2023 18.09.2005 Frankfurt 6 Sarah sarah.hoffmann@mail.de 25.10.2023 14.02.2006 Stuttgart 7 David david.schulz@mail.de 05.11.2023 08.06.2005 Düsseldorf 8 Lena lena.bauer@mail.de 30.12.2023 27.10.2006 Leipzig Posts
Post-ID Nutzer-ID Inhalt Datum Uhrzeit Likes Kommentare 101 1 Urlaub am Strand 🌊 20.07.2023 14:30 42 8 102 2 Neues Buch gelesen! 📚 22.07.2023 16:45 28 5 103 3 Gestern im Kino gewesen 🎬 23.07.2023 18:20 35 6 104 4 Mein neues Fahrrad 🚴 25.07.2023 12:10 56 12 105 5 Konzert war mega! 🎵 28.07.2023 20:15 89 15 106 6 Selbstgemachte Pizza 🍕 30.07.2023 19:30 64 9 107 7 Wanderung im Schwarzwald 🏞️ 02.08.2023 15:40 33 4 108 8 Neues Handy ausgepackt 📱 05.08.2023 11:25 47 7 109 1 Zoo-Besuch mit Freunden 🦁 08.08.2023 17:10 52 10 110 3 Geburtstagsfeier war super! 🎉 10.08.2023 22:05 78 14 111 5 Neuer Haarschnitt 💇 12.08.2023 13:30 29 3 112 7 Erster Tag im neuen Job 💼 15.08.2023 09:15 61 8 - Die Datenbank der Social-Media-Plattform ist hier als ER-Modell dargestellt und noch um Freundschaften ergänzt worden.
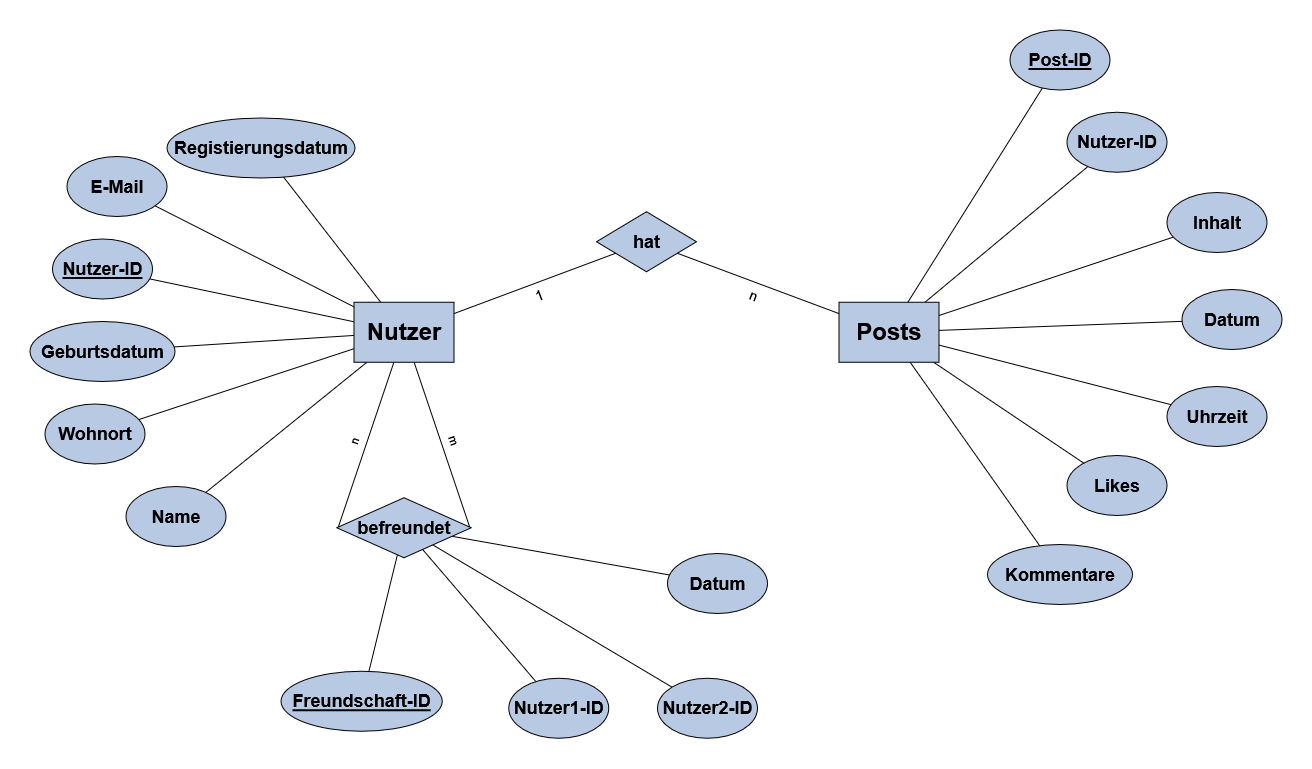
Lade dir hier das Bild des ER-Modells herunter und beschrifte das ER-Modell mit den passenden Fachbegriffen aus dem Video.
Erstellen aus dem ER-Modell das relationale Schema, soweit dir das möglich ist. Bei den Stellen, wo du es nicht kannst, notiere dir, was dich an einer Überführung hindert.
Beschreibe die Entitäten "Nutzer" und "Posts" sowie die zugehörigen Beziehung unter Verwendung der Fachbegriffe.
Eine 1:1-Beziehung ist bisher nicht in dem ER-Modell enthalten.
Erweitere das ER-Modell mit einer passenden 1:1-Beziehung in dem Social-Media-Kontext.
Lade dir hier das Bild der Tabellen herunter und beschrifte die Tabellen mit den passenden Fachbegriffen, wie du es in dem Video gesehen hast.
Erstellen aus der Datenbank das relationale Schema.
Beschreibe die Tabelle "Posts" unter Verwendung der Fachbegriffe.
Bei der Überführung des ER-Modells in eine konkrete Datenbank muss man bei den Relationen besonders aufpassen. Denn diese müssen bei der Überführung in das relationale Datenbankschema besonder berücksichtigt werden.
- 1:1-Beziehung
- Bei einer 1:1 Beziehung nehmen wir den Primärschlüssel einer der beiden Relationen und setzen ihn bei der anderen Relation als Fremdschlüssel ein.
Beispiel: Jeder Nutzer hat für sich Einstellungen getätigt und die spezifischen Einstellungen gehören zu einem Nutzer.Um das Modell nun in das relationale datenbankschema zu überführen, geben wir der Tabelle Einstellungen noch den Primärschlüssel von Nutzer als Fremdschlüssel und somit erhalten wir folgendes relationales Datenbankschema: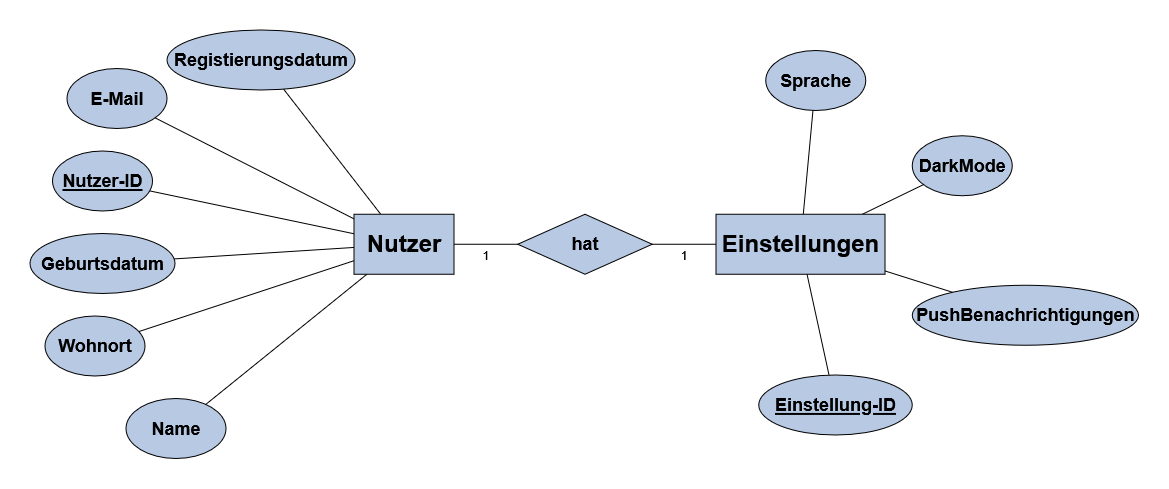
1:1-Relation
Nutzer(Nutzer-ID, Name, Wohnort, Geburtstdatum, E-Mail, Registrierungsdatum)
Einstellungen(Einstellung-ID, ⭡Nutzer-ID, Sprache, DarkMode, PushBenachrichtigungen) - 1:n-Beziehung
- Bei einer 1:n Beziehung nehmen wir den Primärschlüssel der 1-er Relation und setzen ihn als Fremdschlüssel in die n-Relation ein.
Beispiel: Nutzer können beliebig viele Posts verfassen, aber jeder Post gehört nur zu einer Person.Wie in dem ER-Modell bereits berücksichtigt, erhält die Tabelle bei der Überführung zum relationalen Datenbankschema den Primärschlüssel der Tabelle Nutzer als Fremdschlüssel, da bei Posts die n-Relation ist: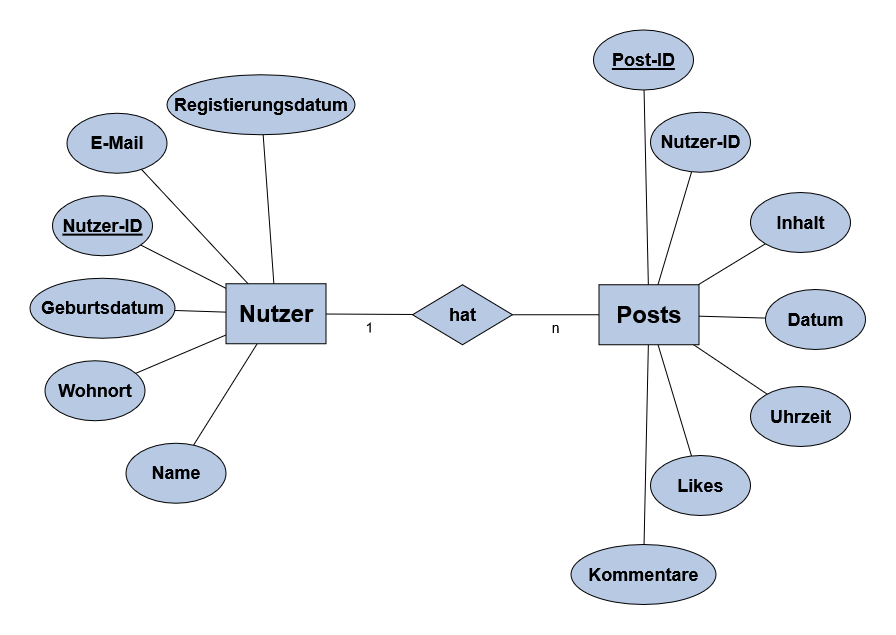
1:n-Relation
Nutzer(Nutzer-ID, Name, Wohnort, Geburtstdatum, E-Mail, Registrierungsdatum)
Posts(Post-ID, ⭡Nutzer-ID, Inhalt, Datum, Uhrzeit, Likes, Kommentare) - n:m-Beziehung
- Bei einer n:m Beziehung wird eine zusätzliche Relation (Zuordnungstabelle) gebildet, die jeweils die Primärschlüssel der n-Relation und m-Relation als Fremdschlüssel enthält.
Beispiel: In diesem Beispiel können mehrere Nutzer miteinander befreundet sein. Wir müssen hier ein neue Tabelle erzeugen, die die Relationbefreundetwiderspiegelt - nennen wir sieFreundschaften. Damit nun abgebildet werden kann, dass ein Nutzer mit einem anderen Nutzer befreundet ist, erhält die Tabelle zwei Mal den Primärschlüssel von Nutzer als Fremdschlüssel (Attributsnamen dürfen nciht identisch sein).
n:m-Relation Nutzer(Nutzer-ID, Name, Wohnort, Geburtstdatum, E-Mail, Registrierungsdatum)
Freundschaften(Freundschaft-ID, ⭡Nutzer1-ID, ⭡Nutzer2-ID)
- Gib das relationale Datenbankschema des folgende ER-Modells an.
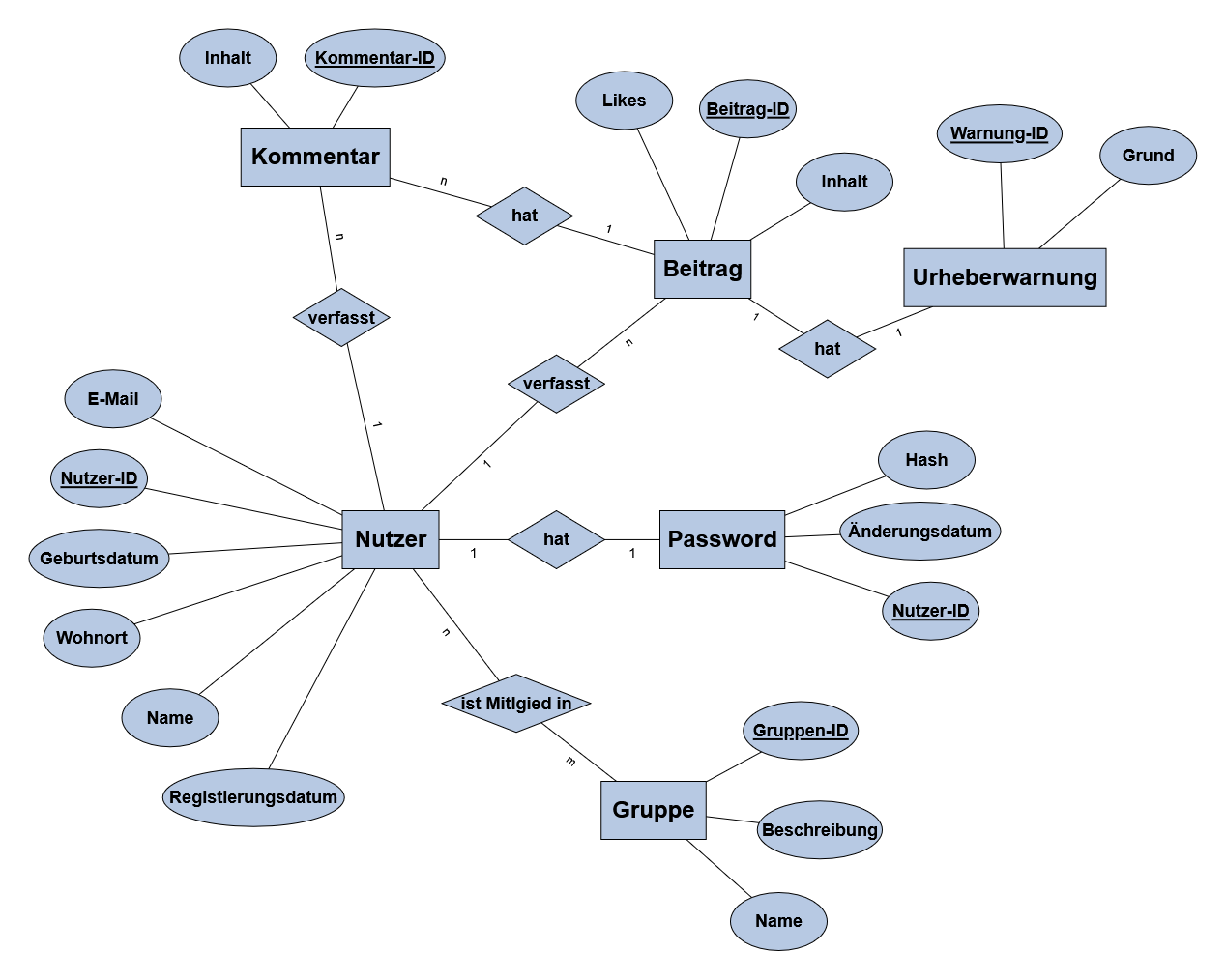
ER-Modell: Social-Media - Erweitere das folgende ER-Modell, um die beschriebenen Sachverhalte.Du kannst das ER-Modell hierüber öffnen.
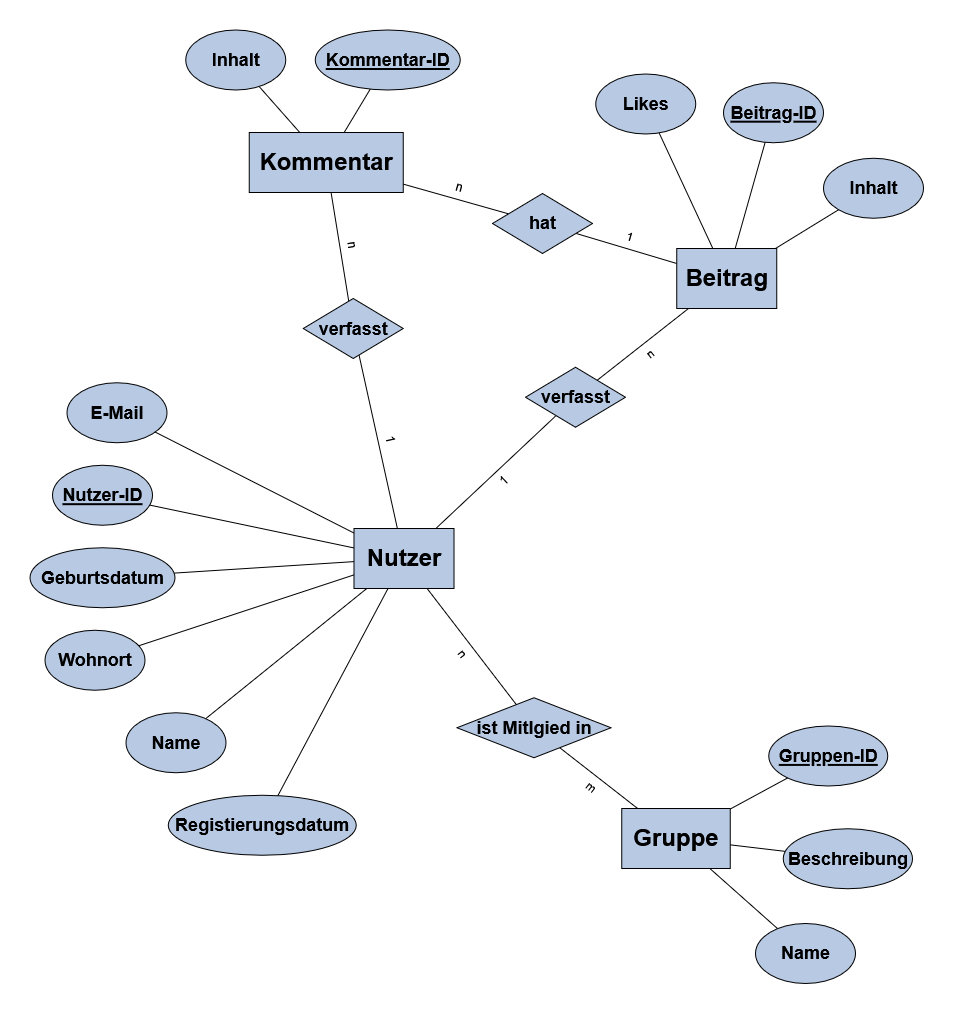
ER-Modell: Social-Media Beiträgen können gegen Urheberrecht verstoßen (s. Aufgabe 1) und genauso können auch Kommentare dagegen verstoßen.
Ergänze entsprechend die Entität und die Beziehung.Die Social-Media-Plattform muss natürlich auch Freundschaftsanfrage verwalten. Jede Freundschaftsanfrage ist durch eine ID, den Absender und Empfänger der Anfrage, einem Status und einem Datum gekennzeichnet.
Erweitere das ER-Modell um die Entität und die Beziehung.Natürlich arbeitet unsere Social-Media-Plattform auch mit Hashtags, diese haben eine ID und einen Namen. Wie man sich vorstellen kann, können Beiträge mit Hashtags versehen werden.
Erweitere das ER-Modell entsprechend.In Beiträgen können Nutzer markiert werden.
Erweitere das ER-Modell entsprechend.Aus unklaren Gründen möchte Nutzer auf mal ihr Profil löschen. Dazu wurde die Löschanfrage erstellt, die sich Datum, Grund und Status der Anfrage speichert und mit dem Nutzer verbunden ist.
Erweitere das ER-Modell um die Entität und die Beziehung.Manchmal müssen Nutzer ihre Beiträge nachträglich bearbeiten. Dabei kann es ein, dass sie mehrmals ihren Beitrag verändern. Um dieses zu protokollieren, gibt es eine Beitragshistorie. Dabei wird sich jedes Mal nur der letzte alte Inhalt gemerkt und wann der Beitrag geändert wurde.
Erweitere das ER-Modell um die Entität und die Beziehung.Gib das relationale Datenbankschema für dein ER-Modell an.
Komplexe Suchanfragen sind mit einfachen Projektionen und Selektionen nicht umzusetzen. Oft
möchte man Daten sortiert ausgeben oder Berechnungen innerhalb der Attributswerte durchführen.
Hinter der WHERE-Klausel wurde bisher mit dem Gleichheitszeichen jeweils ein einzelner Attributswert
verglichen. Es sind jedoch weitaus mehr Operationen möglich, von denen die wichtigsten nun
gezeigt werden.
| Operator | Erläuterung |
|---|---|
| < | kleiner |
| > | größer |
| <= | kleiner oder gleich |
| >= | größer oder gleich |
| <> | ungleich |
| BETWEEN | Ist der Wert innerhalb eines bestimmten Wertebereichs? |
| LIKE | Enthalten die durchsuchten Attributswerte einen vorgegebenen Teil? Das Zeichen % meint beliebig viele und _ genau ein Zeichen. |
| IN | Alle Attributswerte werden mit einer vorgegebenen Liste überprüft. |
| IS NULL | Ist der Attributswert mit einem Wert gefüllt oder leer? |
Betrachten wir einige der Operatoren an unseren Beispieltabellen Buch und Film:
| Buch | |||
|---|---|---|---|
| ISBN | Titel | Autor | Preis (€) |
| 978-3-608-93800-5 | Der Hobbit | J.R.R. Tolkien | 24,00 |
| 978-3-453-52842-0 | Ich, der Roboter | Isaac Asimov | 10,00 |
| 978-0-785-83983-5 | A Tale of Two Cities | Charles Dickens | 11,99 |
| Film | ||||
|---|---|---|---|---|
| EAN | Titel | FSK | Preis (€) | Buch |
| 5051890300027 | Der Hobbit | 12 | 44,99 | 978-3-608-93800-5 |
| 4045167015739 | James Bond - Spectre | 12 | 29,99 | |
| 4020628814274 | Great Barrier Reef | 0 | 13,29 | |
Zeige alle Autoren an, deren Bücher mit einem Buchstaben von A bis D beginnen.
SELECT Autor
FROM Buch
WHERE Titel < 'E';→
| Autor |
|---|
| J.R.R. Tolkien |
| Charles Dickensn |
Zeige alle Filme an, die zwischen 25 und 50 Euro kosten.
SELECT Titel
FROM Film
WHERE Preis BETWEEN 25 AND 50;→
| Titel |
|---|
| Der Hobbit |
| James Bond - Spectre |
Zeige alle Bücher an, deren Titel 'er' beinhaltet.
SELECT Titel
FROM Buch
WHERE Titel LIKE '%er%';→
| Titel |
|---|
| Der Hobbit |
| Ich, der Roboter |
Schreibt man %er, werden alle Titel ausgegeben, welche am Ende er haben, also nur Ich, der Roboter. Schreibt man er%, werden alle ausgegeben, die er am Anfang haben, also keine. Schreibt man %er%, werden alle Titel ausgegeben, die irgendwo die Zeichenkette er beinhalten.
Zeige alle Filme an, die 13,29 oder 29,99 kosten.
SELECT Titel
FROM Film
WHERE Preis IN (13.29, 29.99);→
| Titel |
|---|
| James Bond - Spectre |
| Great Barrier Reef |
Zeige alle Filme an, deren Attributswerte von Buch leer sind.
SELECT Titel
FROM Film
WHERE Buch IS NULL;→
| Titel |
|---|
| James Bond - Spectre |
| Great Barrier Reef |